说明
本文只实现一个最基本推荐功能,其可以实时分析用户的行为并据此提取推荐线索,从而根据最新的用户线索利用搜索引擎获取推荐结果。
本策略缺少以下基本能力:
- 被推荐物品之间缺乏关联关系,某种意义上不能推荐与当前物品相似的物品。
- 只对用户行为进行定性分析,非定量。比如用户看了“口腔溃疡”十次、看了“感冒一次”,这两者却获得了相同的加权。
- 缺乏推荐后用户行为的反馈。
实现思路
该推荐功用于“轻问诊”场景中向用户推荐感兴趣的医生。基本思路是把用户的行为日志逐条读入Storm中,根据用户当前关心的疾病名、医生科室线索推荐符合条件的医生给用户。
用户行为日志来源: 来自为App提供数据接口的服务器,拦截用户的全部请求并抽取requestUrl和requestParameters就满足了获取用户(userId)感兴趣的疾病或科室(请求参数)的目标。
日志传输路径:log -(flume)-> Kafka –> Storm –> Redis –> ElasticSearch。
具体实现
各组件物理拓扑
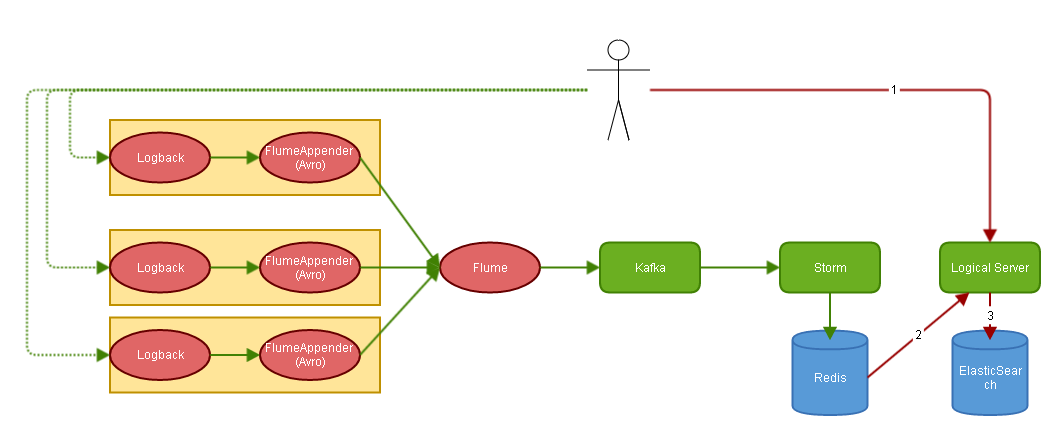
图中分为绿色线条和红色线条两部分。
绿色线条部分是用户的行为日志处理:
- 首先使用拦截器拦截所有用户请求,整理出必需参数交给logback记录日志——此处包含两个Appender:RollFileAppender和FlumeAppender,前者是传统日志文件(存本地),后者是日志收集组件(Flume)能够在保证可靠性的前提下高效地将多个host的日志汇聚到Flume Agent处,再由Flume Agent提交给kafka。
- Storm通过KafkaSpout逐条抽取提交到消息服务的日志并实时处理,处理结果根据UserId生成唯一Key保存在Redis中供推荐服务查询。
红色部分是推荐行为:
- 用户触发推荐行为后服务器根据UserId从Redis获取所有该用户的推荐线索——疾病名称、科室Id等。
- LogicalServer根据当前用户的线索,生成合适的查询条件调用搜索引擎获取推荐结果。比如:根据疾病名在医生擅长项目中查找、根据科室线索筛选口碑好的医生等。
除此之外用户的行为日志具有时效性,在Storm处理过程中会保留用户日志的原始数据,根据日志发生时间判断是否要将某一条日志保留或删除。
Storm中的Topology
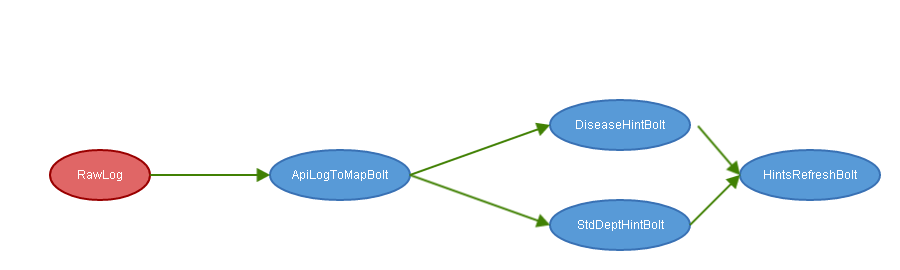
进入Kafka的数据格式是未经处理的日志数据(包括logback的layout处理),本部分首先开发了一个根据layout信息逆转日志为结构化数据的工具(暂时命名为log-delayout,未来日志介绍)用来把日志转换成结构化的数据。
ApiLogToMapBolt负责文本日志到结构化数据的转换,除此之外ApiLogToMapBolt还起到过滤的作用把不感兴趣的日志直接排除掉,减轻系统负担。
从ApiLogToMapBolt出来的Tuple会根据Url的特征值分发到DiseaseHintBolt(疾病)或StdDeptHintBolt(科室)中,在这两个Bolt中完成关键信息的提取过程——提取疾病或科室Id、更新数据到Redis中、同时删除已经超过时效性的记录。
最后通知HintsRefreshBolt根据最新的用户特征刷新推荐信息,以便下次服务器查询时能够获得最新的推荐条件。